
What Access is Needed for Effective Auditing? Insights from Near-Verbatim Extraction on Open-Weight Models
AVERI’s mission is to make frontier AI auditing effective and universal. By this, we mean that we’d like to see rigorous third-party verification of frontier AI developers’ safety and security claims, and evaluation of their systems and practices against relevant standards, based on deep, secure access to non-public information.
A. Feder Cooper, Research Scientist at AVERI, recently posted a preprint that advances scientific understanding of training data memorization by language models, and in the process, sheds light on what kind of access auditors will likely need in practice to better understand how much frontier models memorize.
The Importance of Memorization
Language models memorize a portion of their training data. The extent of such memorization can signal important things about model behavior and capabilities, including overfitting to the training data. How much memorization is happening, and whether it’s feasible to extract memorized data in outputs, matters for additional safety and security reasons: extraction can expose private data, leak information that could be abused for malicious purposes, or reproduce copyrighted material present in the training data.
Memorization is not the only thing that matters in AI safety and security, but it’s a key building block to fully understanding an AI system’s risk profile. Consider an analogy to assessing security at a bank. A bank needs better security if it has more stored in its vault. If the bank manager hires a consultant to advise on improving security, the consultant couldn’t really do their job effectively if they didn’t have at least a rough sense of how hard a thief might try to break in.
Likewise, in order to know the stakes of many AI safety and security interventions (such as increasing robustness to “jailbreaks”), it’s important to know how often language models are actually generating new insights on the fly versus nearly exactly reproducing something they read somewhere, and how much knowledge they have about a range of topics.
This analogy also helps clarify why it’s important to also study base models (or models that have been “pre-trained” on largely Internet-derived data, but not “post-trained” to behave as a helpful assistant). The post-training process can conceal or reduce the likelihood of undesirable knowledge or behaviors emerging (such as memorized training data), but it often doesn’t actually remove that knowledge entirely or make the behavior impossible. Studying base models can give a sense of worse-case degrees of potential extraction risk.
Verbatim and Near-Verbatim Extraction
On a technical level, memorization means that a language model assigns a very high probability to a particular sequence of “tokens” (words or chunks of words) in its training data. The way that researchers typically quantify this behavior is through extraction: reproducing memorized training data at generation time through prompting the model in specific ways.
The standard way that researchers measure extraction has (at least) two blind spots. First, these methods are typically used only to count exact (verbatim) matches. Prompt a model with a “prefix” from a known training sequence, generate a continuation, and check whether it matches the training data (the “target suffix”) exactly – token-for-token. If even one token is off – a punctuation mark, a space – it doesn't get counted as extraction. Prior work shows this misses memorized sequences that the model reproduces with near-perfect fidelity, which can similarly pose privacy, safety, or copyright issues.
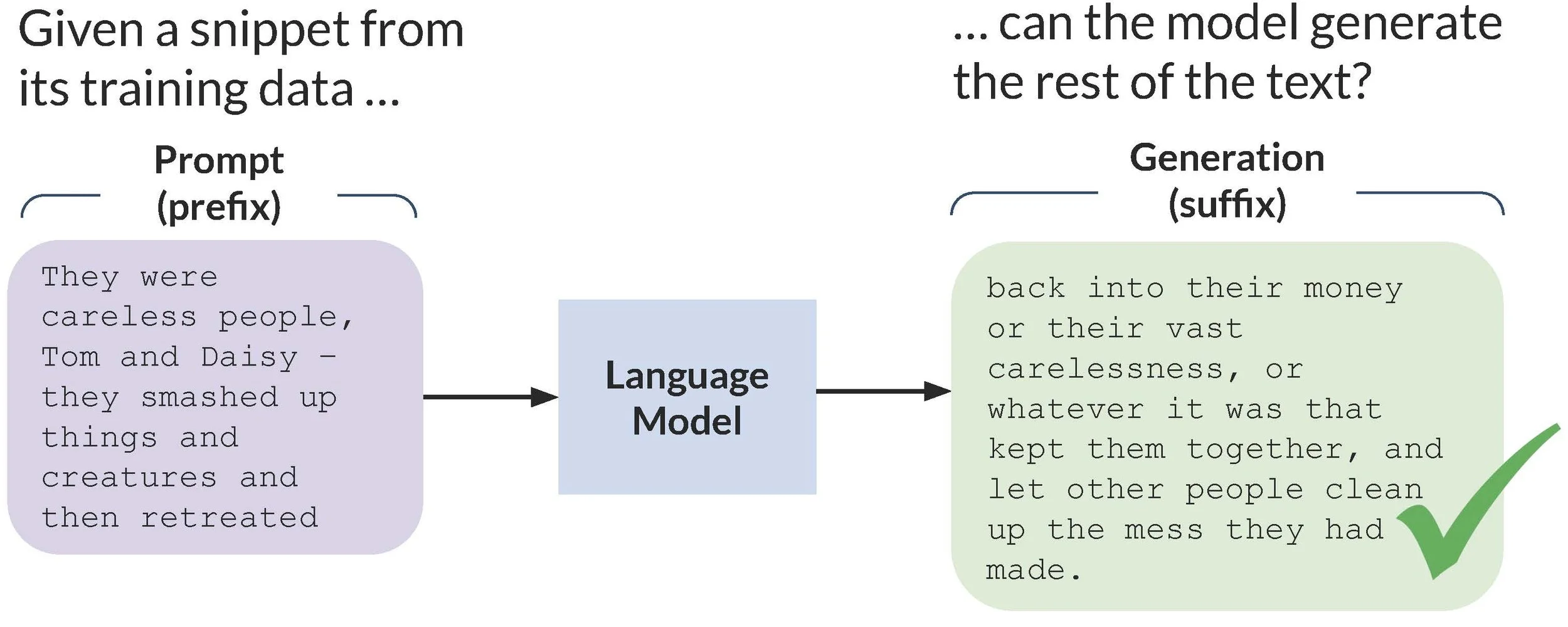
Fig. 1. Illustrating extraction of a sequence of training data from The Great Gatsby. Figure reproduced from Cooper et al. (2025).
Second, it typically uses greedy decoding: during generation, this produces the locally highest-probability token for each token in the output. This is deterministic – you always get the same generation for the same prompt – and produces a binary outcome: extracted or not (Fig. 1). But in practice, LLMs use non-deterministic decoding schemes, so the relevant question isn't whether a sequence can be extracted, but how likely extraction is on any given generation. A sequence the model reproduces 15% of the time poses very different leakage risk than one it reproduces 0.1% of the time. As prior work shows for verbatim extraction, that probability – the extraction risk– provides a lot more information than a yes/no determination about extraction.
Our new paper addresses both of the above limitations together. We introduce a tractable method for estimating near-verbatim extraction risk: the probability that a model, when prompted with a prefix, generates a continuation that is within a small edit distance of the suffix.
Experiments on open-weight models show that accounting for near-verbatim extraction reveals far more memorized training data and much higher extraction risk than verbatim methods suggest.
We find that models can produce near-exact copies of their training data that differ by trivial edits such as spacing and punctuation ("money— that" vs. "money—that") and hyphenation ("honeycomb" vs. "honey-comb"). The memorization is clearly real, but the model encoded slightly different forms of the same text, instead of putting all (or, sometimes, even most of) the probability on the verbatim target suffix being tested. This means that just looking at verbatim risk can conceal how much meaningful (near-verbatim) extraction risk there actually is.
These are all cases where verbatim extraction tests say "not extracted," but the model has clearly reproduced the training data in its outputs. And because each of these near-verbatim variants carries its own probability of generation, the total extraction risk – the chance of producing any near-copy – can be far larger than the probability of producing the exact original.

Make it stand out
Fig. 2. For Llama 1 13B and the same training sequence as in Fig. 1 from The Great Gatsby, we show the training prefix, three continuations generated using top-k (temperature = 1, k = 40), and the probability of generating each continuation given the prefix under top-k. We visually diff the characters in each continuation with the target suffix’s characters. Blue shows text in the generation that isn’t present in the target suffix (additions), and red shows text missing from the generation that’s present in the target suffix (deletions). Quantitatively, we compute the edit distance, comparing each tokenized continuation to the tokenized target suffix. We highlight in yellow the case of verbatim extraction of the target suffix, which is not the greedy continuation that the traditional extraction method returns (the top row). All three continuations are near-verbatim matches to the target suffix. Figure reproduced from Cooper et al. (2026).
In Fig. 2, we show what this looks like for Llama 1 13B and the same quote from The Great Gatsby that’s in Fig. 1. Traditional greedy-decoded extraction would return the continuation in the top row, which would fail a verbatim check (but pass even a very stringent near-verbatim one). Verbatim extraction risk would capture the middle row: this is the verbatim suffix (edit distance = 0). A probability of 0.1431 means that, when prompted with the prefix, Llama 1 13B outputs the suffix verbatim about 1 out of every 7 times (under top-k decoding; 1/0.1431 times ∼1/7). But all three variations are clearly almost identical to the verbatim target suffix. Outputting any one of them would indicate extraction risk. So the relevant risk – the near-verbatim risk – is actually the sum of the probabilities over all of the near-verbatim continuations. In this case, the near-verbatim risk associated with just these three continuations is 0.1477 + 0.1431 + 0.0671 = 0.3579, which is 2.5x the verbatim risk!
Why is near-verbatim extraction risk hard to estimate?
One can compute verbatim extraction risk exactly for a cost comparable to doing greedy decoding.¹ But for near-verbatim, it’s not so simple. To compute it exactly, you need the total probability mass on all continuations within some maximum edit distance of the target suffix. And that set is enormous. For a 50-token sequence, allowing for just two token edits means that there are over a trillion near-verbatim suffixes to evaluate.²
An alternative is to actually sample from the model with the chosen decoding scheme: prompt the model a bunch of times and count how often the output lands close enough to the target suffix. This works, and is cheaper than brute-forcing every possible near-verbatim sequence, but is still wildly expensive. Detecting a sequence with a 1% near-verbatim extraction risk (which is really high for a language model) requires roughly 300 samples; reliably estimating it requires around 10,000.³ So at scale this is still impractical.
Our deterministic and tractable estimation approach
We introduce decoding-constrained beam search, which exploits a key property of memorized sequences: they are high-probability under the model. Beam search is a decoding algorithm that deterministically explores a high-probability region of the output space, so we intuited that, for memorized sequences, it should surface near-verbatim continuations.
We make some modifications to beam search to operate under a chosen decoding scheme (e.g., top-k with k = 40), so each candidate continuation comes with its exact probability under that scheme. We then filter the outputs of the search for continuations within a chosen edit distance of the training-data suffix, and sum their probabilities to produce a deterministic lower bound on near-verbatim extraction risk. It's guaranteed to be correct, requires no repeated sampling, and costs roughly the same as 20 samples (instead of thousands).⁴
What we find
We ran experiments across three different open-weight model families (OLMo 2, Llama 2, Pythia), covering different model sizes and different types of text data from their respective training datasets (Wikipedia, public domain books, Enron emails, respectively). We also ran a series of negative controls: experiments on non-training, where we expect to see no extraction (which would support the validity of our extraction procedure).
Verbatim methods substantially undercount extraction (and memorization). For one example (Fig. 3), our experiments on OLMo 2 32B and 10,000 training sequences from Wikipedia find that 2.57% of sequences are near-verbatim extractable with our method, compared to 1.42% for verbatim probabilistic extraction and 0.61% for the standard greedy method. The sequences that verbatim methods miss have very high risk – on average, over 0.08 (a high number for an LLM).
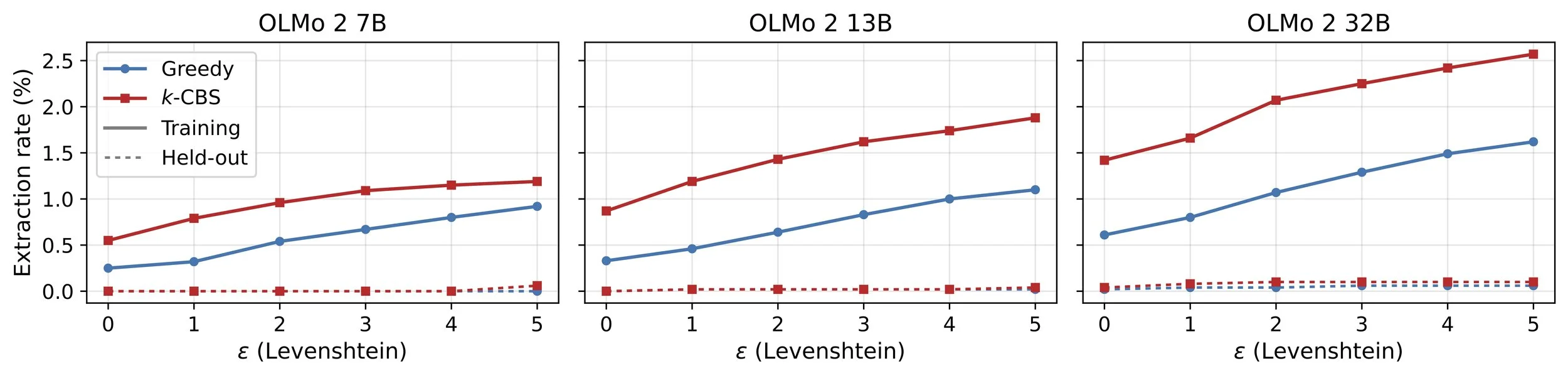
Fig. 3. Evaluating extraction for the OLMo 2 model family, which has 7B, 13B and 32B model sizes. Each plot shows extraction rates for a different model size, for verbatim (maximum distance ε = 0) and near-verbatim extraction (k-CBS) for edit distance (Levenshtein) with maximum distances ε ∈ {1, 2, 3, 4, 5}. For greedy near-verbatim extraction, one generates the single greedy continuation and checks if the distance with the target suffix doesn’t exceed ε. We use a sample of 10,000 sequences from Wikipedia from OLMo 2’s training data. To assess validity, we also run analogous negative controls on 5,000 held-out sequences scraped from Wikipedia that post-date OLMo 2’s training cutoff. The greedy extraction rates are all exact. The probabilistic extraction rates use decoding-constrained beam search, and so these rates should be interpreted as lower bounds on the true extraction rates. Figure reproduced from Cooper et al. (2026).
Near-verbatim extraction risk is much larger for individual sequences. The example sequence from The Great Gatsby (Fig. 2) already suggests this: near-verbatim extraction risk is often significantly larger than the verbatim risk. For that sequence, decoding-constrained beam search returns a lower bound of 0.7155 – over 4x the verbatim risk of 0.1431! The model outputs a near-verbatim copy of the suffix over 7 out of every 10 times it’s prompted with the prefix. In many cases, sequences with no verbatim risk have enormous near-verbatim risk – in extreme cases, going from 0 to over 0.85. This degree and variation of extraction risk is entirely invisible to verbatim and greedy methods.
The undercount grows with model size. As expected, we can extract more sequences from larger models. But, similar to the original work on verbatim probabilistic extraction, we also find that as model size increases, greedy extraction and verbatim extraction become worse undercounts of total extraction. (You can see this in Fig. 3: the gaps between rates widen.)
Implications for Audit Access
These results are on open-weight models, but the implications extend well beyond them.
For open-weight models, researchers automatically have full access to output probabilities. This is what makes decoding-constrained beam search possible: we can score every candidate continuation exactly. Furthermore, open-weight model releases often include base models.
Extending our technique to closed models would require access to log-probabilities or logits – not the full weights, but at least the output distributions for base models, which our method needs for producing and scoring continuations. Even limited access, such as returning log-probabilities for a set of provided continuations and chosen decoding scheme, could enable far more informative extraction audits than black box sampling.
Since this access is rare today, our research implies that frontier AI auditors would require privileged access to be specifically provided by the frontier AI company in order to conduct an audit where memorization was an important consideration, of which we believe there are likely to be several (e.g., measuring overfitting on evaluation tasks, estimating near-verbatim knowledge of certain facts with significant misuse risk like scientific facts from virology, etc.). More generally, over time, the limitations of relying on publicly available information and interfaces are growing, not shrinking, as we argued in our launch paper.
These findings have immediate relevance for policy implementation. For example, the EU AI Act’s Code of Practice requires “adequate access” to be provided to third-party evaluators. And while there are not yet frontier AI auditing requirements in the US, proposals for such requirements would have to either specify access requirements, or use general terms like adequate access that will then need to be interpreted based on the available scientific evidence. Notably, our findings suggest the necessity of base model access for many purposes, but not the sufficiency – frontier models are increasingly post-trained with significant amounts of data and computing power, which can add new knowledge and behaviors. Understanding what is learned at this stage would require different techniques than those discussed here.
This preprint is not the only line of evidence supporting the need for deep access in order to conduct effective audits. Indeed, much of the evidence for this comes from companies themselves, such as when they describe safety interventions that are only possible with access to model internals and training data as well as model chains-of-thought. Deep access for auditors need not mean unrestricted access: in many cases, the right standard is secure, claim-scoped access that gives auditors only the privileged visibility needed to analyze a specific safety or security claim, using time-bound, rate-limited model interfaces and data query tools.
We are optimistic that deep, secure access is ultimately a solvable problem. Frontier AI auditing is challenging primarily because the technology itself is being developed and deployed rapidly, not because there is no precedent for such deep access in other contexts, or because there aren’t promising techniques for providing access in a way that protects sensitive intellectual property (see our launch paper for related discussion). But if we are to achieve effective and universal frontier AI auditing in a timely fashion, frontier AI companies will need to provide deep access to systems and information about company practices. We hope to share more in the coming months about the practical aspects of providing this access under mutually agreeable terms.
Notes
¹ You can run the whole verbatim sequence through the LLM, and use the logits to compute the exact probability of the target suffix given the prefix, according to a chosen decoding scheme.
² It’s intractable to run them all through the verbatim procedure, and then tally up their probabilities. But it also shouldn’t be necessary to do that. Many near-verbatim suffixes will have 0 or extremely low probability. Consider replacing the token for “ the” with the token for “ jazz” or “ github” near the end of the target suffix from The Great Gatsby.
³ For lower risk sequences, these numbers are even higher.
⁴ We also develop variants that integrate the distance check directly into the search, often yielding tighter bounds at lower cost. The preprint covers in detail why the different variants of decoding-constrained beam search produce a valid lower bound on extraction risk for a given sequence, why those bounds are also useful in practice, and why our algorithm is cheaper than sampling.