
What Access is Needed for Effective Auditing? Insights from Near-Verbatim Extraction on Open-Weight Models
A new method for studying near-verbatim memorization in language models that has implications for access requirements in frontier AI auditing
AVERI’s mission is to make frontier AI auditing effective and universal. By this, we mean that we’d like to see rigorous third-party verification of frontier AI developers’ safety and security claims, and evaluation of their systems and practices against relevant standards, based on deep, secure access to non-public information.
A. Feder Cooper, Research Scientist at AVERI, recently posted a preprint that advances scientific understanding of training data memorization by language models, and in the process, sheds light on what kind of access auditors will likely need in practice to better understand how much frontier models memorize.
The Importance of Memorization
Language models memorize a portion of their training data. The extent of such memorization can signal important things about model behavior and capabilities, including overfitting to the training data. How much memorization is happening, and whether it’s feasible to extract memorized data in outputs, matters for additional safety and security reasons: extraction can expose private data, leak information that could be abused for malicious purposes, or reproduce copyrighted material present in the training data.
Memorization is not the only thing that matters in AI safety and security, but it’s a key building block to fully understanding an AI system’s risk profile. Consider an analogy to assessing security at a bank. A bank needs better security if it has more stored in its vault. If the bank manager hires a consultant to advise on improving security, the consultant couldn’t really do their job effectively if they didn’t have at least a rough sense of how hard a thief might try to break in.
Likewise, in order to know the stakes of many AI safety and security interventions (such as increasing robustness to “jailbreaks”), it’s important to know how often language models are actually generating new insights on the fly versus nearly exactly reproducing something they read somewhere, and how much knowledge they have about a range of topics.
This analogy also helps clarify why it’s important to also study base models (or models that have been “pre-trained” on largely Internet-derived data, but not “post-trained” to behave as a helpful assistant). The post-training process can conceal or reduce the likelihood of undesirable knowledge or behaviors emerging (such as memorized training data), but it often doesn’t actually remove that knowledge entirely or make the behavior impossible. Studying base models can give a sense of worse-case degrees of potential extraction risk.
Verbatim and Near-Verbatim Extraction
On a technical level, memorization means that a language model assigns a very high probability to a particular sequence of “tokens” (words or chunks of words) in its training data. The way that researchers typically quantify this behavior is through extraction: reproducing memorized training data at generation time through prompting the model in specific ways.
The standard way that researchers measure extraction has (at least) two blind spots. First, these methods are typically used only to count exact (verbatim) matches. Prompt a model with a “prefix” from a known training sequence, generate a continuation, and check whether it matches the training data (the “target suffix”) exactly – token-for-token. If even one token is off – a punctuation mark, a space – it doesn't get counted as extraction. Prior work shows this misses memorized sequences that the model reproduces with near-perfect fidelity, which can similarly pose privacy, safety, or copyright issues.
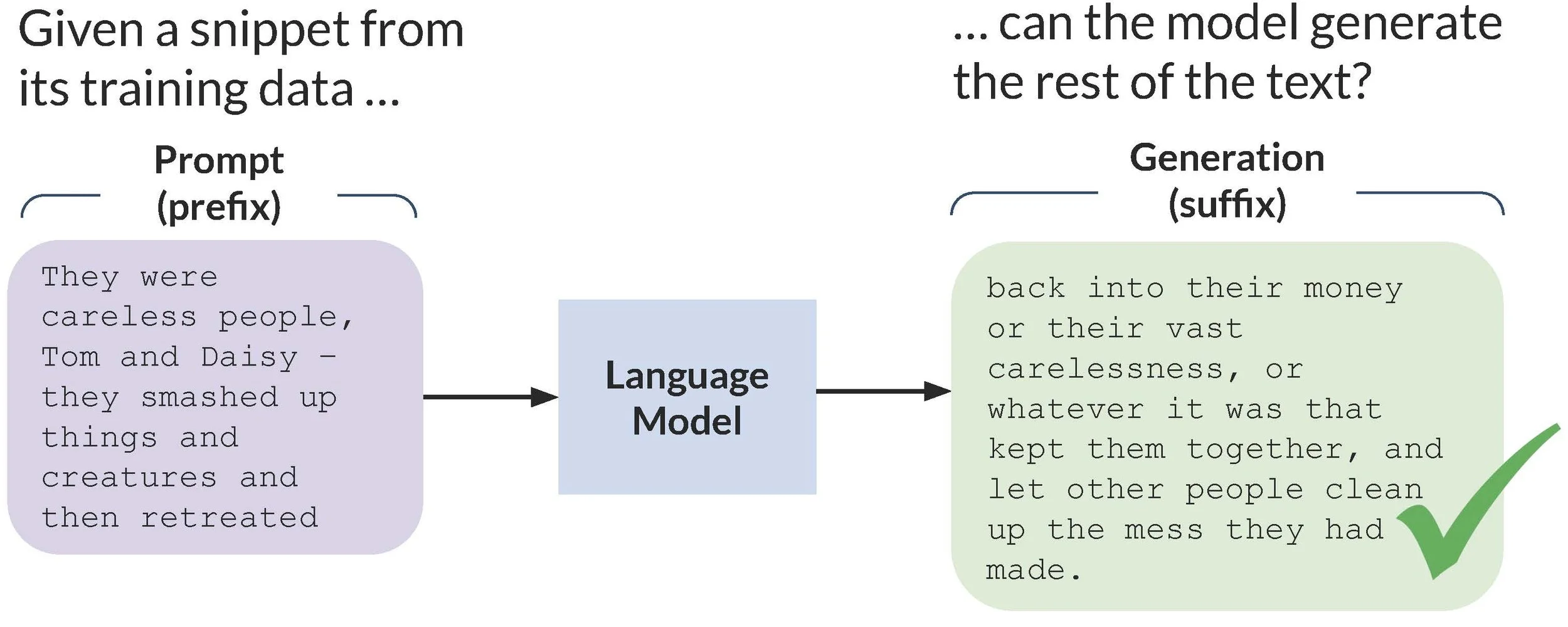
Fig. 1. Illustrating extraction of a sequence of training data from The Great Gatsby. Figure reproduced from Cooper et al. (2025).
Second, it typically uses greedy decoding: during generation, this produces the locally highest-probability token for each token in the output. This is deterministic – you always get the same generation for the same prompt – and produces a binary outcome: extracted or not (Fig. 1). But in practice, LLMs use non-deterministic decoding schemes, so the relevant question isn't whether a sequence can be extracted, but how likely extraction is on any given generation. A sequence the model reproduces 15% of the time poses very different leakage risk than one it reproduces 0.1% of the time. As prior work shows for verbatim extraction, that probability – the extraction risk– provides a lot more information than a yes/no determination about extraction.
Our new paper addresses both of the above limitations together. We introduce a tractable method for estimating near-verbatim extraction risk: the probability that a model, when prompted with a prefix, generates a continuation that is within a small edit distance of the suffix.
Experiments on open-weight models show that accounting for near-verbatim extraction reveals far more memorized training data and much higher extraction risk than verbatim methods suggest.
We find that models can produce near-exact copies of their training data that differ by trivial edits such as spacing and punctuation ("money— that" vs. "money—that") and hyphenation ("honeycomb" vs. "honey-comb"). The memorization is clearly real, but the model encoded slightly different forms of the same text, instead of putting all (or, sometimes, even most of) the probability on the verbatim target suffix being tested. This means that just looking at verbatim risk can conceal how much meaningful (near-verbatim) extraction risk there actually is.
These are all cases where verbatim extraction tests say "not extracted," but the model has clearly reproduced the training data in its outputs. And because each of these near-verbatim variants carries its own probability of generation, the total extraction risk – the chance of producing any near-copy – can be far larger than the probability of producing the exact original.

Make it stand out
Fig. 2. For Llama 1 13B and the same training sequence as in Fig. 1 from The Great Gatsby, we show the training prefix, three continuations generated using top-k (temperature = 1, k = 40), and the probability of generating each continuation given the prefix under top-k. We visually diff the characters in each continuation with the target suffix’s characters. Blue shows text in the generation that isn’t present in the target suffix (additions), and red shows text missing from the generation that’s present in the target suffix (deletions). Quantitatively, we compute the edit distance, comparing each tokenized continuation to the tokenized target suffix. We highlight in yellow the case of verbatim extraction of the target suffix, which is not the greedy continuation that the traditional extraction method returns (the top row). All three continuations are near-verbatim matches to the target suffix. Figure reproduced from Cooper et al. (2026).
In Fig. 2, we show what this looks like for Llama 1 13B and the same quote from The Great Gatsby that’s in Fig. 1. Traditional greedy-decoded extraction would return the continuation in the top row, which would fail a verbatim check (but pass even a very stringent near-verbatim one). Verbatim extraction risk would capture the middle row: this is the verbatim suffix (edit distance = 0). A probability of 0.1431 means that, when prompted with the prefix, Llama 1 13B outputs the suffix verbatim about 1 out of every 7 times (under top-k decoding; 1/0.1431 times ∼1/7). But all three variations are clearly almost identical to the verbatim target suffix. Outputting any one of them would indicate extraction risk. So the relevant risk – the near-verbatim risk – is actually the sum of the probabilities over all of the near-verbatim continuations. In this case, the near-verbatim risk associated with just these three continuations is 0.1477 + 0.1431 + 0.0671 = 0.3579, which is 2.5x the verbatim risk!
Why is near-verbatim extraction risk hard to estimate?
One can compute verbatim extraction risk exactly for a cost comparable to doing greedy decoding.¹ But for near-verbatim, it’s not so simple. To compute it exactly, you need the total probability mass on all continuations within some maximum edit distance of the target suffix. And that set is enormous. For a 50-token sequence, allowing for just two token edits means that there are over a trillion near-verbatim suffixes to evaluate.²
An alternative is to actually sample from the model with the chosen decoding scheme: prompt the model a bunch of times and count how often the output lands close enough to the target suffix. This works, and is cheaper than brute-forcing every possible near-verbatim sequence, but is still wildly expensive. Detecting a sequence with a 1% near-verbatim extraction risk (which is really high for a language model) requires roughly 300 samples; reliably estimating it requires around 10,000.³ So at scale this is still impractical.
Our deterministic and tractable estimation approach
We introduce decoding-constrained beam search, which exploits a key property of memorized sequences: they are high-probability under the model. Beam search is a decoding algorithm that deterministically explores a high-probability region of the output space, so we intuited that, for memorized sequences, it should surface near-verbatim continuations.
We make some modifications to beam search to operate under a chosen decoding scheme (e.g., top-k with k = 40), so each candidate continuation comes with its exact probability under that scheme. We then filter the outputs of the search for continuations within a chosen edit distance of the training-data suffix, and sum their probabilities to produce a deterministic lower bound on near-verbatim extraction risk. It's guaranteed to be correct, requires no repeated sampling, and costs roughly the same as 20 samples (instead of thousands).⁴
What we find
We ran experiments across three different open-weight model families (OLMo 2, Llama 2, Pythia), covering different model sizes and different types of text data from their respective training datasets (Wikipedia, public domain books, Enron emails, respectively). We also ran a series of negative controls: experiments on non-training, where we expect to see no extraction (which would support the validity of our extraction procedure).
Verbatim methods substantially undercount extraction (and memorization). For one example (Fig. 3), our experiments on OLMo 2 32B and 10,000 training sequences from Wikipedia find that 2.57% of sequences are near-verbatim extractable with our method, compared to 1.42% for verbatim probabilistic extraction and 0.61% for the standard greedy method. The sequences that verbatim methods miss have very high risk – on average, over 0.08 (a high number for an LLM).
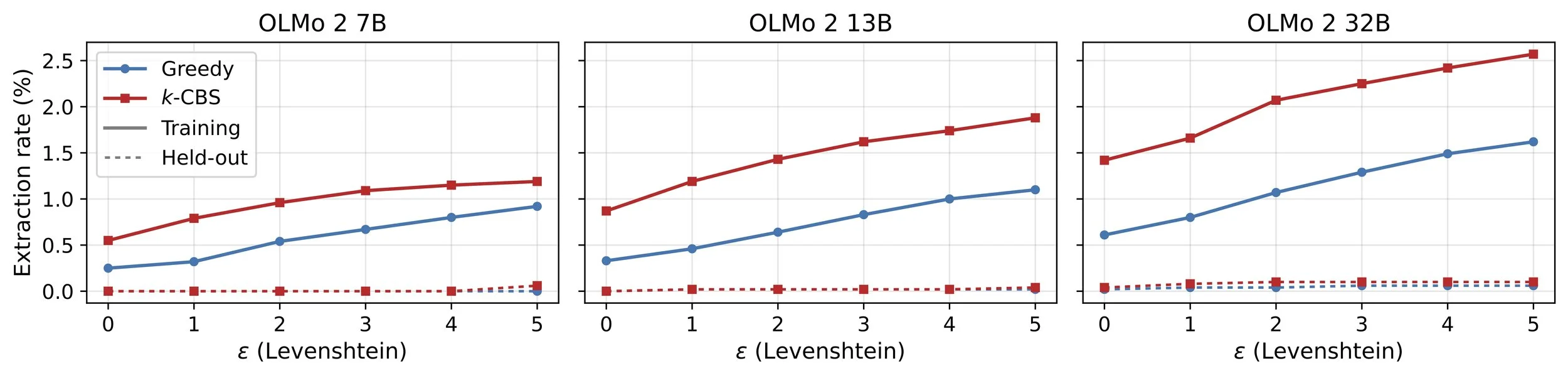
Fig. 3. Evaluating extraction for the OLMo 2 model family, which has 7B, 13B and 32B model sizes. Each plot shows extraction rates for a different model size, for verbatim (maximum distance ε = 0) and near-verbatim extraction (k-CBS) for edit distance (Levenshtein) with maximum distances ε ∈ {1, 2, 3, 4, 5}. For greedy near-verbatim extraction, one generates the single greedy continuation and checks if the distance with the target suffix doesn’t exceed ε. We use a sample of 10,000 sequences from Wikipedia from OLMo 2’s training data. To assess validity, we also run analogous negative controls on 5,000 held-out sequences scraped from Wikipedia that post-date OLMo 2’s training cutoff. The greedy extraction rates are all exact. The probabilistic extraction rates use decoding-constrained beam search, and so these rates should be interpreted as lower bounds on the true extraction rates. Figure reproduced from Cooper et al. (2026).
Near-verbatim extraction risk is much larger for individual sequences. The example sequence from The Great Gatsby (Fig. 2) already suggests this: near-verbatim extraction risk is often significantly larger than the verbatim risk. For that sequence, decoding-constrained beam search returns a lower bound of 0.7155 – over 4x the verbatim risk of 0.1431! The model outputs a near-verbatim copy of the suffix over 7 out of every 10 times it’s prompted with the prefix. In many cases, sequences with no verbatim risk have enormous near-verbatim risk – in extreme cases, going from 0 to over 0.85. This degree and variation of extraction risk is entirely invisible to verbatim and greedy methods.
The undercount grows with model size. As expected, we can extract more sequences from larger models. But, similar to the original work on verbatim probabilistic extraction, we also find that as model size increases, greedy extraction and verbatim extraction become worse undercounts of total extraction. (You can see this in Fig. 3: the gaps between rates widen.)
Implications for Audit Access
These results are on open-weight models, but the implications extend well beyond them.
For open-weight models, researchers automatically have full access to output probabilities. This is what makes decoding-constrained beam search possible: we can score every candidate continuation exactly. Furthermore, open-weight model releases often include base models.
Extending our technique to closed models would require access to log-probabilities or logits – not the full weights, but at least the output distributions for base models, which our method needs for producing and scoring continuations. Even limited access, such as returning log-probabilities for a set of provided continuations and chosen decoding scheme, could enable far more informative extraction audits than black box sampling.
Since this access is rare today, our research implies that frontier AI auditors would require privileged access to be specifically provided by the frontier AI company in order to conduct an audit where memorization was an important consideration, of which we believe there are likely to be several (e.g., measuring overfitting on evaluation tasks, estimating near-verbatim knowledge of certain facts with significant misuse risk like scientific facts from virology, etc.). More generally, over time, the limitations of relying on publicly available information and interfaces are growing, not shrinking, as we argued in our launch paper.
These findings have immediate relevance for policy implementation. For example, the EU AI Act’s Code of Practice requires “adequate access” to be provided to third-party evaluators. And while there are not yet frontier AI auditing requirements in the US, proposals for such requirements would have to either specify access requirements, or use general terms like adequate access that will then need to be interpreted based on the available scientific evidence. Notably, our findings suggest the necessity of base model access for many purposes, but not the sufficiency – frontier models are increasingly post-trained with significant amounts of data and computing power, which can add new knowledge and behaviors. Understanding what is learned at this stage would require different techniques than those discussed here.
This preprint is not the only line of evidence supporting the need for deep access in order to conduct effective audits. Indeed, much of the evidence for this comes from companies themselves, such as when they describe safety interventions that are only possible with access to model internals and training data as well as model chains-of-thought. Deep access for auditors need not mean unrestricted access: in many cases, the right standard is secure, claim-scoped access that gives auditors only the privileged visibility needed to analyze a specific safety or security claim, using time-bound, rate-limited model interfaces and data query tools.
We are optimistic that deep, secure access is ultimately a solvable problem. Frontier AI auditing is challenging primarily because the technology itself is being developed and deployed rapidly, not because there is no precedent for such deep access in other contexts, or because there aren’t promising techniques for providing access in a way that protects sensitive intellectual property (see our launch paper for related discussion). But if we are to achieve effective and universal frontier AI auditing in a timely fashion, frontier AI companies will need to provide deep access to systems and information about company practices. We hope to share more in the coming months about the practical aspects of providing this access under mutually agreeable terms.
Notes
¹ You can run the whole verbatim sequence through the LLM, and use the logits to compute the exact probability of the target suffix given the prefix, according to a chosen decoding scheme.
² It’s intractable to run them all through the verbatim procedure, and then tally up their probabilities. But it also shouldn’t be necessary to do that. Many near-verbatim suffixes will have 0 or extremely low probability. Consider replacing the token for “ the” with the token for “ jazz” or “ github” near the end of the target suffix from The Great Gatsby.
³ For lower risk sequences, these numbers are even higher.
⁴ We also develop variants that integrate the distance check directly into the search, often yielding tighter bounds at lower cost. The preprint covers in detail why the different variants of decoding-constrained beam search produce a valid lower bound on extraction risk for a given sequence, why those bounds are also useful in practice, and why our algorithm is cheaper than sampling.
Frontier AI Auditing-Related Legislation in the US: Landscape, Challenges, and a Path Forward
AVERI’s first endorsement of specific legislation
Note: this article has not been updated to reflect legislative updates since its publication on April 20, 2026. Among other relevant updates, the AI Safety Measures Act in Illinois (a descendant of the bill we endorsed below) was signed into law and starts requiring audits in 2028. Also, a discussion draft of the federal Great American AI Act includes detailed auditing provisions.
AI capabilities are advancing much faster than the scrutiny applied to this critical technology. A justified sense that AI companies are generally “checking their own homework” on safety and security fuels public skepticism and makes organizations more hesitant to deploy AI in high-stakes domains.
Self-assessment of AI safety and security, however well-intended and well-documented, cannot fully resolve the inherent conflict of interest at play. Bias does not require bad faith: sincere developers may unconsciously frame risks in ways that their existing mitigations already address. External auditors can more even-handedly compare practices across firms and bring a perspective less shaped by any one company's internal assumptions and culture.
While some companies voluntarily engage with third parties, voluntary uptake will continue to be uneven by default and to the extent auditing involves real costs, voluntariness could disadvantage the very companies trying to be proactive.
We and others have therefore proposed requiring that third-party auditors verify the claims that AI companies make about their technology and evaluate AI systems and company practices against relevant standards. Currently, there is no state or federal requirement to do this in the US – many legislators and AI company employees worry that auditing requirements would hinder innovation and that there aren't enough qualified auditors.
This post surveys the landscape of legislation related to auditing in the US and then summarizes the challenges that critics of audit requirements have pointed out. We then outline a path forward that addresses these challenges, and highlight the first audit-related bill that AVERI has chosen to endorse.
Terminology
In line with our paper, “Frontier AI Auditing,” we use assessment as an umbrella term for analysis by third parties of a leading AI company’s systems and practices. Assessments involve one or both of two activities: verification of whether a certain claim is true or if a certain commitment is being upheld (e.g., a company following its own safety and security policies), and evaluation of the properties of a system or company’s practices with respect to one or more external standards (e.g., through technical analysis of a model or review of safety processes).

We believe that frontier AI auditing should involve a mix of verification and evaluation – independent auditors should be given access to non-public information that allows them to verify whether companies are doing what they say they’re doing and to evaluate systems and practices against applicable external standards. For the purposes of this post, though, we treat all requirements for external assessment as “audit-related” even if they don’t include all the elements of our definition.
The Legislative Landscape
As of today, the U.S. landscape includes a mix of enacted transparency laws, vetoed and proposed audit requirements, proposals to create voluntary audit frameworks, and the commissioning of a report on a voluntary framework.
Among other elements of these laws, SB 53 in California (currently in force) and the RAISE Act in New York (taking effect in 2027) require companies to have and publish safety and security policies. SB 53 and the RAISE Act also require companies to disclose what role, if any, third-party evaluators play in their safety and security practices. These are important foundations (e.g., auditors could verify whether safety and security policies are being followed, and if third parties are involved, transparency about the process can help inform other companies on how to follow suit). And the RAISE Act goes slightly further by requiring that policies be detailed. But neither actually requires working with third parties and neither has a substantive quality bar for safety and security policies.
Most recently, Virginia’s HB 797 directed the Joint Commission on Technology and Science to study the feasibility and impact of an Independent Verification Organization (IVO) framework, which would give liability benefits in exchange for participation in a voluntary audit regime. It does not itself establish that framework, though the report – due later this year – will be a valuable resource.
Several proposed bills would go further, but have not been passed or signed into law for reasons we discuss in the next section. The table below summarizes the landscape of enacted, defeated, and proposed audit-related legislation. We omit some arguably relevant legislation — for example, requirements for governmental rather than private testing and legislation not focused on frontier AI systems.
| Legislation | Impact | Trigger | Type of risks addressed | Standard | Status |
|---|---|---|---|---|---|
| SB 53 (California, 2025) | Light encouragement via transparency | Developers meeting compute thresholds (1026 FLOPs) and revenue thresholds ($500 million) | Catastrophic risks | N/A | Enacted (in force now) |
| RAISE Act (New York, 2025) | Slightly stronger encouragement via transparency | Developers meeting compute thresholds (1026 FLOPs) and revenue thresholds ($500 million) | Catastrophic risks | N/A | Enacted (in force next year) |
| SB 1047 (California, 2024) | Requirement (annual) | Developers who trained a model meeting compute threshold (1026 FLOPs) and training expense threshold ($100 million) | Catastrophic risks | Not posing “unreasonable risks of causing or materially enabling critical harms” | Vetoed |
| SB 813 (California), HB 628 (Ohio) – grouped together due to similarities | Create a voluntary Independent Verification Organization (IVO) framework | N/A (voluntary) | Personal injury, reasonably foreseeable harm, property damage | Government-certified IVOs would develop standards | Pending |
| HB 797 (Virginia) | Study the creation of an Independent Verification Organization (IVO) framework | N/A (voluntary) | Personal injury, property damage | Government-certified IVOs would develop standards | Enacted |
| HB 4668 (Michigan, 2025) | Requirement (annual) | Developers meeting training expense threshold for one model ($5M) and overall compute expense threshold ($100M in the past 12 months) | Catastrophic risks | Verification against own policies | Pending |
| VET AI Act (federal) | Create voluntary auditing standards | N/A (voluntary) | Privacy, harm mitigation, data quality, documentation and communication, and governance | Out of scope (the focus is on standards for the auditing process rather than standards for safety and security itself) | Pending |
| HB 3506 (Illinois, 2025) | Requirement (annual) | Developers meeting training expense threshold ($100M) | Catastrophic risks | Verification against own policies | Did not pass legislature |
| HB 4705/SB 3261 (Illinois, 2026) | Requirement (annual) | Developers meeting compute thresholds (1026 FLOPs) and revenue thresholds ($500 million) | Catastrophic risks and child safety | Verification against own policies | Pending (discussed further in final section) |
Challenges with Audit Requirements
In response to the bills above and others (e.g., earlier versions of the RAISE Act that included audit requirements), AI companies, their trade associations, and aligned commentators have often opposed audit requirements. We explain the most critical objections that have been raised below, before proposing ways to address them.
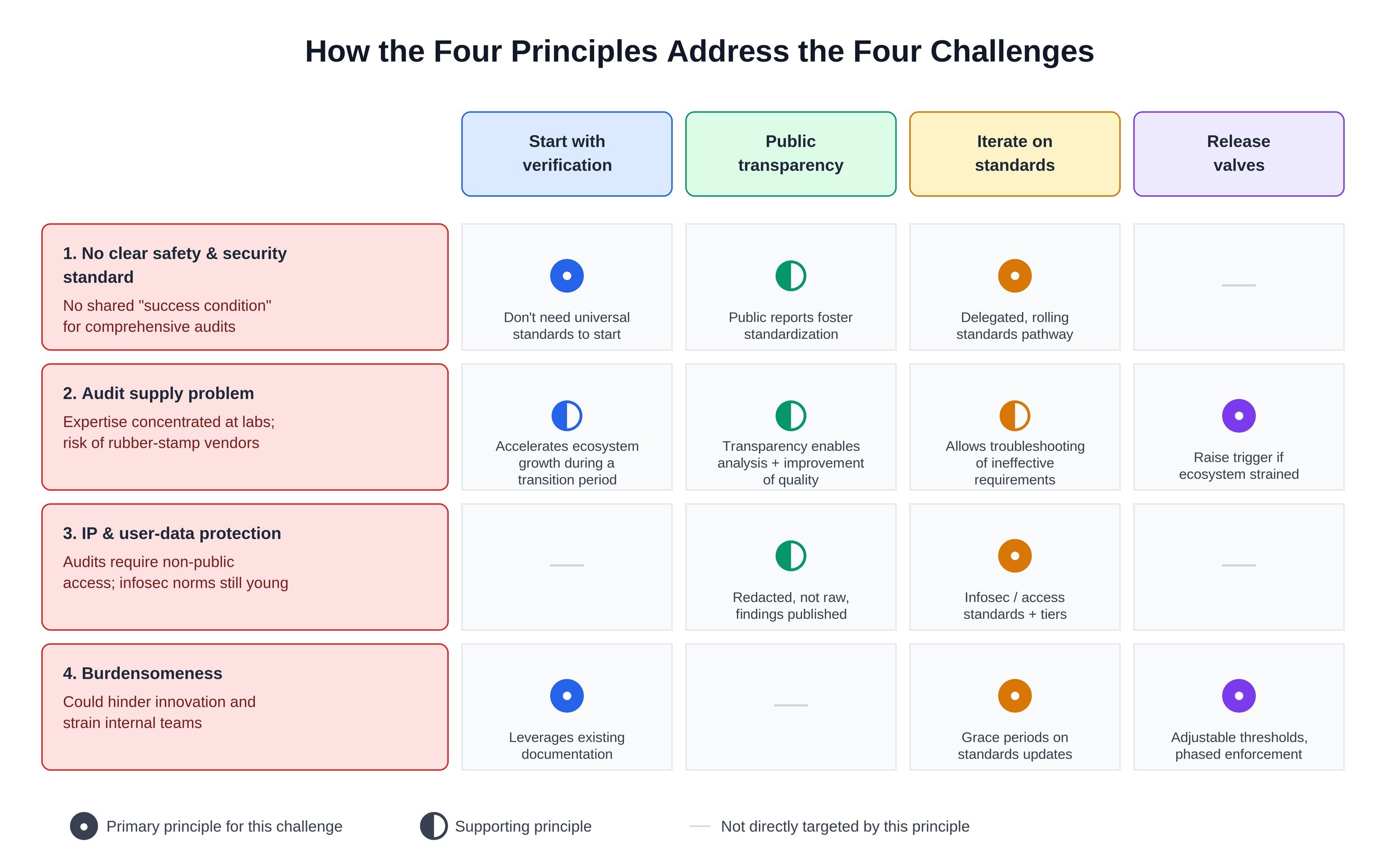
First, companies point to the lack of a clear standard for safety and security against which their systems and practices can be measured. Without such standards, some companies worry, audit results may raise concerns among customers without actually driving progress toward industry-wide safety and security. In other words, there is no clear “success condition” for a comprehensive audit (one that goes beyond verifying compliance with a company’s own policies), making planning for such audits difficult. Companies worry that decontextualized findings will generate confusion and reputational harm without producing much real safety and security value.
Second, companies have expressed concern about an audit supply problem: who will carry out these audits, and with what expertise? A big fraction of expertise on frontier AI is concentrated in the very companies being audited, and what outside expertise exists could be stretched thin by requiring too many audits too quickly. If that happens, unqualified vendors could rush into the market offering “rubber stamp” audits which create a false sense of confidence or detract from more important safety and security investments.
Third, companies worry about protecting sensitive intellectual property and user data, since auditing by definition involves access to non-public information. The recently launched AI Evaluator Forum has begun to articulate initial standards for appropriate access, and in our work we have discussed different tiers of access and related information protections. But given the early state of these standard-setting processes, it is reasonable for companies to worry that the nascent auditor ecosystem might do a poor job protecting the critical information that auditors would sometimes be entrusted with in the course of an audit, particularly if too many audits are required at too many companies too soon.
Finally, there is the problem of burdensomeness. Companies worry that audits will hinder innovation by creating excessive compliance burdens. Without careful design, audits could impose large time burdens on already-stretched internal teams, and could disproportionately burden smaller companies. For example, audits might require employees to perform engineering work in order for auditors to access certain information securely, gather extensive documentation of or produce novel summaries of certain processes, or be interviewed about company systems and practices.
A Path Forward
The challenges described above are real but surmountable. And the high stakes of insufficient scrutiny demand that we find a path forward.
Well-designed public policies can move us, step by step, toward effective and universal frontier AI auditing, and avoid a race to the bottom on safety and security. Below we propose four principles that can inform the design of legislation that requires frontier AI auditing.
Note that we assume in each case that these requirements will be layered on top of existing transparency requirements like SB 53 and the RAISE Act, so we will not repeat some of the key points that arose when crafting such requirements (e.g., the need for focusing on the leading AI companies, which partially addresses the concern about burdensomeness disproportionately affecting small companies).
The figure below summarizes how our four principles help overcome the challenges discussed above.
Start by verifying compliance with company policies
Waiting for comprehensive, industry-wide safety and security standards before getting started would be a mistake given the rapid pace of AI’s development and deployment, and the urgency of many related risks. Fortunately, universal standards aren’t needed in order to get started.
The path forward involves building on what already exists: company-level policies on safety and security. Auditors can verify companies’ compliance with their own policies and share appropriately redacted versions of their findings, building institutional capacity that can later support auditing against industry-wide standards.
Setting a clear timeline for this kind of verification will help stimulate growth and investment in the auditing ecosystem. Importantly, while verification is a key first step, company policies may be too weak by default, so this transition phase should not last forever. The same legislation can set one timeline for verifying compliance with companies’ own policies and a separate, later timeline for evaluation against common standards.
Lean into public transparency
Under the definitions used above, an audit involves assessing non-public information, and that specific information can’t be published by auditors. But the redacted versions of audit findings and details on the audit process should be published in order to hold auditors publicly accountable for conducting rigorous analysis rather than checkbox exercises.
Note that this principle differs from some proposals under which auditors would send audit reports only to regulators – an approach we think could encourage checkbox compliance due to limited feedback loops. Regulators should have access to unredacted results, but public redacted results are necessary in order to build an industry-wide understanding of AI safety and security.
For example, an auditor's report might note that a company withheld certain information on the grounds of that information being sensitive and that, as a result, the auditor could not determine whether a key policy commitment had been met. Publishing that conclusion would not itself reveal the confidential company information, but it would provide fodder for public discussion about the balance between assurance and burdensomeness, and direct researcher attention towards better privacy-preserving access mechanisms.
Similarly, auditors should be required to publish credentials and disclosures of conflicts of interest. This transparency will help enable informed discussion of audit supply, demand, and quality.
Iterate on standards
Rather than writing detailed rules for safety and security – and for the auditing process itself – into legislation today, policymakers can instead designate one or more sources of formal standards or more informal best practices (we refer to both categories collectively as “standards” below). For example, legislation might require a government official or agency to either promulgate standards or designate a source of standards, and to do so six months after passage of the legislation. There may be multiple organizations involved in sorting out the details of such standards – e.g., one organization could be responsible for defining audit process standards and another could be responsible for defining information security standards.
Various public and private organizations exist that could produce or inform standards for AI safety and security and auditing thereof. These include the Center for AI Standards and Innovation (CAISI), the Frontier Model Forum, and the AI Evaluator Forum. Illustratively, CAISI could promulgate official standards on safety and security and the auditing thereof; the Frontier Model Forum (a group of leading AI companies) could be a source of standards for internal risk mitigations and for different components of safety and security policies, which could inform CAISI standards; and the AI Evaluator Forum (a group of assessment organizations) could also be a source of input for CAISI’s standards or a source of standards in its own right. Many permutations are possible, though the key takeaway here is that there are foundations to build on.
To balance rapid iteration with regulatory predictability, standards could be applied in a rolling fashion with grace periods. For example, suppose that a standard is updated in the middle of an ongoing audit. Audit legislation could give companies the option of either immediately switching to a new set of standards or completing an ongoing audit using the prior set of standards for up to one quarter after the announcement.
Early in the development of frontier AI auditing, the most urgent issues should be prioritized for standardization – ones that directly relate to key challenges discussed above. For example, establishing a clear way of adjudicating disagreements between companies and auditors about access and redaction should be a high priority, whereas standardizing audit report formats is less critical in the near term, as long as key components are somehow included in the reports.
Bake in release valves
Clear deadlines and economic incentives would focus attention and investment in the auditing ecosystem, so we are optimistic that the audit supply problem can be solved relatively quickly (e.g., we believe that it would be reasonable to require 5-10 frontier AI companies to be audited starting in early 2027). There is significant latent capacity (e.g., in academia) that can be brought to bear in achieving this or even more ambitious auditing timelines, and there is a growing network of for-profit and non-profit assessment organizations. But it is impossible to predict which audit providers will emerge by what time with certainty, and audit-related legislation could accommodate this uncertainty through temporary “release valves,” providing flexibility in response to new information – for example, if the auditing ecosystem is straining to meet demand at a high level of quality.
Two key types of release valves that policymakers should consider are:
Adjusting the threshold that triggers audit requirements. If, per credible public research, the audit ecosystem is being stretched too thin as a result of many companies needing to be audited, the threshold for triggering an audit requirement could be raised in order to focus more narrowly on the sources of greatest potential risk.
Delaying enforcement of new standards. If standard-setting bodies don’t move quickly enough for regulators to have confidence in going beyond verification, the verification-only period could be extended.
Release valves would ideally be triggered by objective metrics, to reduce the risk of them being triggered as a result of political pressure. And the further in the future auditing requirements come into force, the less it makes sense to include release valves, since there will be more time to prepare.
Our First Endorsement and Next Steps
An audit requirement based on the principles above would help reduce safety and security risks from AI and build user and investor confidence in this increasingly critical industry.
Getting legislation along those lines passed will require different stakeholders to compromise, and we have been heartened to hear from contacts across industry, civil society, and government that there is openness to such a path.
Toward this end, AVERI recently endorsed legislation for the first time, specifically HB 4705/SB 3261 in Illinois. In line with recent state legislation trends, HB 4705/SB 3261 builds directly on the framework established in SB 53 and the RAISE Act in order to address concerns about a patchwork of conflicting requirements.
This legislation reflects many of the ideas discussed above – for example, it focuses on verification of compliance with companies’ own policies – and would represent significant progress. We are appreciative that the legislators involved are receptive to feedback on how to ensure the legislation creates clear, focused requirements.
We have been glad to see Anthropic also endorse this bill and OpenAI favorably discuss auditing in general in a recent publication. We hope these recent developments indicate the beginning of more robust industry support for auditing, and that the principles above can help us move toward effective and universal frontier AI auditing, step by step. We look forward to continued engagement with various stakeholders about the details of audit requirements and auditing standards.
Scaling Laws Podcast
Why AI Needs Independent Auditors
Summary
AVERI's Executive Director, Miles Brundage, recently appeared on the Scaling Laws podcast. You can listen to the episode here or watch it here.
Mentioned in this episode:
Fortune Exclusive
Former OpenAI policy chief creates nonprofit institute, calls for independent safety audits of frontier AI models
By Jeremy Kahn
Featured on FORTUNE.COM | January 15, 2026, 12:01 PM ET

Former OpenAI policy chief Miles Brundage, who has just founded a new nonprofit institute called AVERI that is advocating for independent AI safety auditing of the top AI labs.
Miles Brundage, a well-known former policy researcher at OpenAI, is launching an institute dedicated to a simple idea: AI companies shouldn’t be allowed to grade their own homework.
Today Brundage formally announced the AI Verification and Evaluation Research Institute (AVERI), a new nonprofit aimed at pushing the idea that frontier AI models should be subject to external auditing. AVERI is also working to establish AI auditing standards.
The launch coincides with the publication of a research paper, coauthored by Brundage and more than 30 AI safety researchers and governance experts, that lays out a detailed framework for how independent audits of the companies building the world’s most powerful AI systems could work.
Frontier AI Auditing: Toward Rigorous Third-Party Assessment of Safety and Security Practices at Leading AI Companies
A comprehensive framework for independent evaluation of frontier AI systems, mapping access requirements to systemic risks.
Miles Brundage¹*, Noemi Dreksler², Aidan Homewood², Sean McGregor¹, Patricia Paskov³, Conrad Stosz⁴, Girish Sastry⁵, A. Feder Cooper¹, George Balston¹, Steven Adler⁶, Stephen Casper⁷, Markus Anderljung², Grace Werner¹, Sören Mindermann⁵, Vasilios Mavroudis⁸, Ben Bucknall⁹, Charlotte Stix¹⁰, Jonas Freund², Lorenzo Pacchiardi¹¹, José Hernández-Orallo¹¹, Matteo Pistillo¹⁰, Michael Chen¹², Chris Painter¹², Dean W. Ball¹³, Cullen O’Keefe¹⁴, Gabriel Weil¹⁵, Ben Harack³, Graeme Finley⁵, Ryan Hassan¹⁶, Scott Emmons⁵, Charles Foster¹², Anka Reuel¹⁷, Bri Treece¹⁸, Yoshua Bengio¹⁹, Daniel Reti²⁰, Rishi Bommasani¹⁷, Cristian Trout²¹, Ali Shahin Shamsabadi²², Rajiv Dattani²¹, Adrian Weller¹¹, Robert Trager³, Jaime Sevilla²³, Lauren Wagner²⁴, Lisa Soder²⁵, Ketan Ramakrishnan²⁶, Henry Papadatos²⁷, Malcolm Murray²⁷, Ryan Tovcimak²⁸
¹AVERI ²GovAI ³Oxford Martin AI Governance Initiative ⁴Transluce ⁵Independent ⁶Clear-Eyed AI ⁷MIT CSAIL ⁸Alan Turing Institute ⁹University of Oxford ¹⁰Apollo Research ¹¹University of Cambridge ¹²METR ¹³Foundation for American Innovation ¹⁴Institute for Law and AI ¹⁵Touro University Law Center ¹⁶New Science ¹⁷Stanford University ¹⁸Fathom
¹⁹Mila, Université de Montréal ²⁰Exona Lab ²¹AI Underwriting Company ²²Brave Software ²³Epoch AI ²⁴Abundance Institute ²⁵interface ²⁶Yale University ²⁷SaferAI ²⁸UL Solutions
January 2026
Listed authors contributed significant writing, research, and/or review for one or more sections. The sections cover a wide range of empirical and normative topics, so with the exception of the corresponding author (Miles Brundage, miles.brundage@averi.org), inclusion as an author does not entail endorsement of all claims in the paper, nor does authorship imply an endorsement on the part of any individual’s organization.
Executive Summary
Key paper takeaways
Despite their rapidly growing importance, AI systems are subject to less rigorous third-party scrutiny than many of the other social and technological systems that we rely on daily such as consumer products, corporate financial statements, and food supply chains. This gap is becoming increasingly untenable as AI becomes more capable and widely deployed, and it inhibits confident deployment of AI in high-stakes contexts.
Transparency alone cannot enable well-calibrated trust in the most capable (“frontier”) AI systems and the companies that build them: many safety- and security-relevant details are legitimately confidential and require expert interpretation, and third parties are right to be skeptical of companies "checking their own homework" given the track record of that approach in other industries.
We outline a vision for frontier AI auditing, which we define as rigorous third-party verification of frontier AI developers’ safety and security claims, and evaluation of their systems and practices against relevant standards, based on deep, secure access to non-public information.
Frontier AI audits should not be limited to a company’s publicly deployed products, but should instead consider the full range of organization-level safety and security risks, including internal deployment of AI systems, information security practices, and safety decision-making processes.
We describe four AI Assurance Levels (AALs), the higher levels of which provide greater confidence in audit findings. We recommend AAL-1 as a baseline for frontier AI generally, and AAL-2 as a near-term goal for the most advanced subset of frontier AI developers.
Achieving the vision we outline will require (1) ensuring high quality standards for frontier AI auditing, so it does not devolve into a checkbox exercise or lag behind changes in the industry; (2) growing the ecosystem of audit providers at a rapid pace without compromising quality; (3) accelerating adoption of frontier AI auditing by clarifying and strengthening incentives; and (4) achieving technical readiness for high AI Assurance Levels so they can be applied when needed.
Frontier AI auditing motivations
Artificial intelligence (AI) is rapidly becoming critical societal infrastructure. Every day, AI systems inform decisions that affect billions of people. Increasingly, they also make consequential decisions autonomously. Although these technologies hold incredible promise, the pace of development and deployment has outpaced the creation of institutions that ensure AI works safely and as advertised.
This institutional gap is especially important for the most capable (“frontier”) systems — general-purpose AI models and systems whose performance is no more than a year behind the state-of-the-art — which many experts expect to exceed human performance across most tasks within the coming years. Already, developers of frontier AI systems need to prevent harmful system failures (e.g., outputting false medical information or buggy code), weaponization by malicious parties (e.g., to carry out cyberattacks), and theft of or tampering with sensitive data. The magnitude of risks that need to be managed is growing rapidly.
AI users, policymakers, investors, and insurers need reliable ways to verify that promised technical safeguards exist and to detect when they do not. This is challenging because the technology is complex, fast-moving, and often proprietary. Public transparency alone cannot solve this problem since many key details are — and often should remain — confidential, and require expert judgment to interpret. Many industries outside of AI already address similar challenges through independent auditors who review sensitive, non-public information and publish trustworthy conclusions that outsiders can rely on. We argue that similar practices are needed in the AI industry: broad, sustainable adoption of AI over time requires a solid foundation of trust built on credible scrutiny by independent experts.
Toward this end, we propose institutions designed to give stakeholders — including those who are uncertain about or even strongly skeptical of frontier AI companies — justified confidence that this critical technology is being developed safely and securely. Specifically, we describe and advocate for frontier AI auditing: rigorous third-party verification of frontier AI developers’ safety and security claims, and evaluation of their systems and practices against relevant standards, based on deep, secure access to non-public information.
An ecosystem of private sector frontier AI auditors (both for-profit and non-profit) would enable widespread confidence that frontier AI systems can be adopted broadly and would avoid reliance on companies “grading their own homework,” an approach with a checkered track record in many industries. It would also avoid relying entirely on governments to have the technical expertise, capacity, and agility to ensure high standards for frontier AI safety and security. If well-executed and scaled, frontier AI auditing would improve safety and security outcomes for users of AI systems and other affected parties, create a system to learn and update standards based on real-world outcomes, and enable more confident investment in and deployment of frontier AI, especially in high-stakes sectors of the economy.
Summary of the proposal
Drawing on our analysis of current practices in AI and lessons from other industries with more mature assurance regimes, we recommend eight interlinked design principles for a long-term vision for frontier AI auditing. This vision is deliberately ambitious to match the rising stakes as frontier AI capabilities advance:
Scope of risks: Comprehensive coverage of four key risk categories. Frontier AI auditing should focus on four risk categories: risks from (1) intentional misuse of frontier AI systems (e.g., for cyberattacks); (2) unintended frontier AI system behavior (e.g., errors harming the user, their property, or third parties due to pursuing the wrong goal or having an unreliable performance profile); (3) information security (e.g., theft of an AI model or user data); and (4) emergent social phenomena (e.g., addiction to AI or facilitation of self-harm). For each category of risks, auditors should (a) verify company claims and (b) evaluate the company’s systems and practices against its stated safety and security policies, applicable regulations, and industry best practices.
Organizational perspective: Auditing companies’ safety and security practices as a whole, not just individual models and systems. Auditors should use an organization-level perspective to avoid abstraction errors (i.e., forming the wrong conclusion by treating a partial or simplified unit of analysis, such as evaluating a specific component in isolation, as if it were sufficient to assess overall system and organizational risk). Risk does not come from AI models alone; it emerges from the interaction of three overarching components: digital systems, computing hardware, and governance practices, and harm can arise even when a model is never deployed in external-facing systems. Rigorous, but isolated, model and system evaluations are therefore insufficient to evaluate all safety and security claims on their own. And while individual audits may focus on particular domains depending on their goals, the ecosystem as a whole should ensure comprehensive coverage across all three components in assessing safety and security claims.
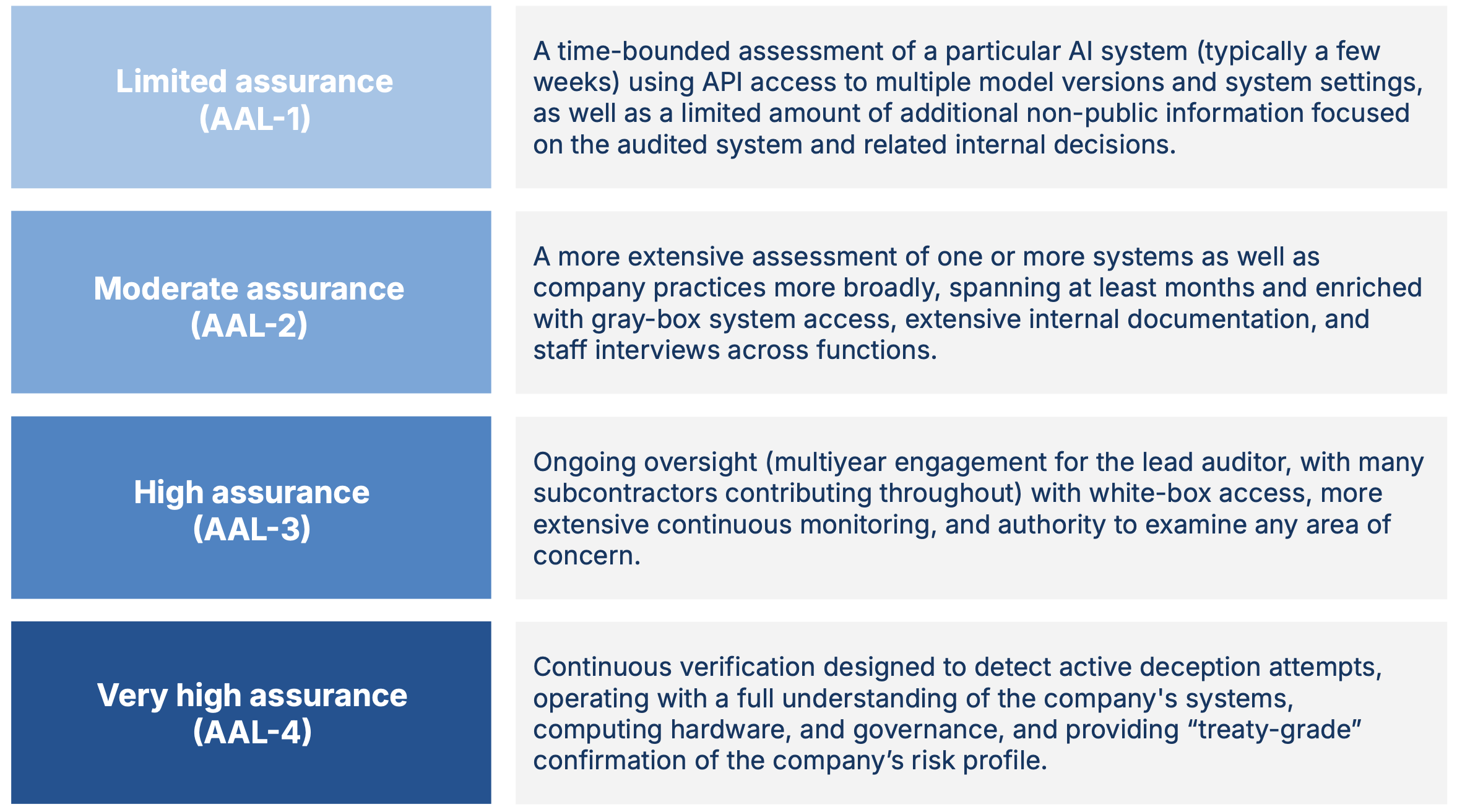
Figure 1: Four AI Assurance Levels (AALs) for different frontier AI audits.
Levels of assurance: A framework for calibrating and communicating confidence in audit conclusions. Not all audits provide the same level of certainty, and stakeholders need to understand these differences. We propose AI Assurance Levels (AALs) as a means of clarifying what kind of assurance particular frontier AI audits provide (Figure 1). At lower levels, auditors and other stakeholders rely more heavily on information provided by the company and can primarily speak to a particular system’s properties. At higher levels, auditors take fewer assumptions for granted, and assess the full range of relevant company systems, organizational processes, and risks. At the highest level, auditors can rule out the possibility of materially significant deception by the auditee. Determining the appropriate AAL for different contexts and purposes is complex, but we recommend AAL-1 (the peak of current practices in AI) as a starting point for frontier AI generally, and AAL-2 as a near-term goal for the companies closest to the state-of-the-art. AAL-2 involves greater access to non-public information, less reliance on companies’ statements, and a more holistic assessment of company-level risks. The two highest assurance levels (AAL-3 and AAL-4) are not yet technically and organizationally feasible, but we outline research directions to change this.
Access: Deep enough to assure auditors and other stakeholders, secure enough to reassure auditees. Frontier AI auditors should receive deep, secure access to non-public information of various kinds — including model internals, training processes, compute allocation, governance records, and staff interviews — proportional to the audit’s scope and the level of assurance being sought for the audit. Access arrangements should protect intellectual property and security-sensitive information using mechanisms imported from other domains (e.g., sharing certain information with a subset of the auditing team on-site under a restrictive nondisclosure agreement) and newly-developed techniques (e.g., AI-powered summarization or analyses of information that is too sensitive to be directly shared).
Continuous monitoring: Living assessments, not stale PDFs. AI systems change constantly, including through adjustments to the underlying model(s), surrounding software, and shifts in user behavior. An audit conclusion that was accurate at the time of the assessment may become misleading in some respects within days or weeks. Audit findings should therefore carry explicit assumptions and validity conditions, and should be automatically deprecated when key underlying assumptions no longer hold. A mature auditing ecosystem will combine periodic deep assessments of slower-moving elements (e.g., governance, safety culture) with event-triggered reviews of major changes (e.g., new releases, serious incidents) and continuous automated monitoring of fast-changing surfaces (e.g., API behavior, configuration drift), enabling timely detection of changes that could invalidate prior conclusions.
Independent experts: Trustworthy results through rigorous independence safeguards and deep expertise. Auditors must be genuinely independent third parties, free from commercial or political influence, and have deep expertise across AI evaluation, safety, security, and governance. Safeguarding independence requires mandatory disclosure of financial relationships, standardized terms of engagement that prevent companies from shopping for favorable auditors, and cooling-off periods when moving, in both directions, between industry and audit roles. Alternative payment models that reduce auditor dependence on auditees should also be urgently explored. Where single auditing organizations lack sufficient expertise, subcontracting and consortia models can enable the necessary breadth across AI evaluation, safety, security, and governance.
Rigor: Processes that are methodologically rigorous, traceable, and adaptive. Audits should follow a standardized process while giving auditors the autonomy to flexibly determine specific methods and adjust scope as issues emerge. Auditors should be able to define evaluation metrics and criteria rather than simply validating companies’ preselected approaches. Wherever feasible, audit procedures should be automated, transparent, and reproducible to support consistent application across engagements and enable continuous monitoring as systems evolve. Auditors need to safeguard evaluation construct and ecological validity, and audit criteria should be protected against gaming. Finally, audits should incorporate procedural fairness, giving companies structured opportunities to correct factual errors while preventing undue influence on conclusions.
Clarity: Clear communication of audit results. Stakeholders must be able to understand the audit results. These should be communicated in audit reports with a standardized structure, covering the audit’s scope, level of assurance, conclusions, reasoning, and recommendations. Results should be communicated appropriately to different stakeholders: to protect sensitive information, auditors and companies can publish summarized or redacted versions for external stakeholders while sharing full, unredacted audit reports with boards, company executives, and, in some cases, regulatory bodies.
Challenges and next steps
Our long-term vision will require concrete efforts by several categories of stakeholders to both achieve and maintain. The most urgent challenges are:
Ensuring high quality standards for frontier AI auditing, so it does not devolve into a checkbox exercise or lag behind changes in the AI industry.
Growing the ecosystem of audit providers at a rapid pace without compromising quality.
Accelerating adoption of frontier AI auditing by clarifying and strengthening incentives.
Achieving technical readiness for high AI Assurance Levels so they can be applied when needed.
These challenges are substantial but not unprecedented. Companies routinely share sensitive information with financial auditors, potential acquirers, penetration testers, and consumer product testing laboratories under carefully controlled terms. We believe similar practices for AI safety and security are both achievable and urgently needed. For each of the challenges we describe, we recommend specific next steps:

Figure 2: Recommendations for next steps across four challenges in frontier AI auditing.
Keeping up with the rapid pace of AI progress and deployment requires quickly importing best practices from more mature industries and immediate investment in auditing pilots, technical research, and policy research. Moving with urgency is essential if frontier AI auditing is to reach maturation and scale alongside AI development.
SHARE ARTICLE:
Measuring Progress on AI Safety Practices
Without reliable measurement of AI systems, we cannot conclude a measured system is safe
AVERI’s purpose (i.e., to make third-party auditing of frontier AI effective and universal) takes inspiration from, among others, the financial industry. However, financial auditors benefit from 700+ years of bookkeeping history. AI safety does not have comparable forms of safety expression against which audits might be conducted. In short, there is no “balance sheet for AI” where frontier AI companies could fill in numbers to arrive at a bottom line finding of safe or unsafe.
Neither AVERI nor the rest of the AI assurance ecosystem has a solution to the “balance sheet problem,” but we can — at least to some extent — measure our progress towards a reliable accounting of AI risk.

Without reliable measurement of AI systems, we cannot conclude a measured system is safe
Measuring the Reliability of Claims
In financial audits, the task is to verify claims of financial condition, but for AI systems, an auditor is tasked with verifying safety and security claims. Consider, for example, the claims below:
| Finance | AI Safety | |
|---|---|---|
| Claim | Liquid cash balance: $12,186,633 | Cybersecurity risk: negligible |
| Examined Evidence | Bank statement | Safety case, benchmarks, evaluations, internal process control documents, red team results, … |
A financial auditor can quickly verify cash on hand by checking bank statements, but safety claims quantitatively and qualitatively integrate many forms of evidence. Without the simplicity of receipts, AI safety claim verification is an exercise in weighing “how likely is this risk model to be wrong?”
In short, verification is an exercise in measuring the risk that safety claims are wrong and reliable evaluations serve to reduce that risk. Strong measures of evaluation reliability therefore enable better evaluations.
Risk Management for Benchmark Evidence: BenchRisk
To enable the measurement of evaluation reliability, we examined benchmarks as artifacts making claims and measured the risk that these claims might mislead people about the properties of a system. We bundled our process, which is a specialized form of risk management processes, into a dataset at BenchRisk.ai and presented the results at NeurIPS 2025.
McGregor, Sean, et al. Risk Management for Mitigating Benchmark Failure Modes: BenchRisk. Proceedings of the Neural Information Processing Systems Conference (NeurIPS), 2025. arXiv, arXiv:2510.21460.
BenchRisk proceeds by collecting failure modes (57 to date) and mitigations (196 to date) whose affirmation by the benchmark author increases the benchmark’s reliability and score of BenchRisk.
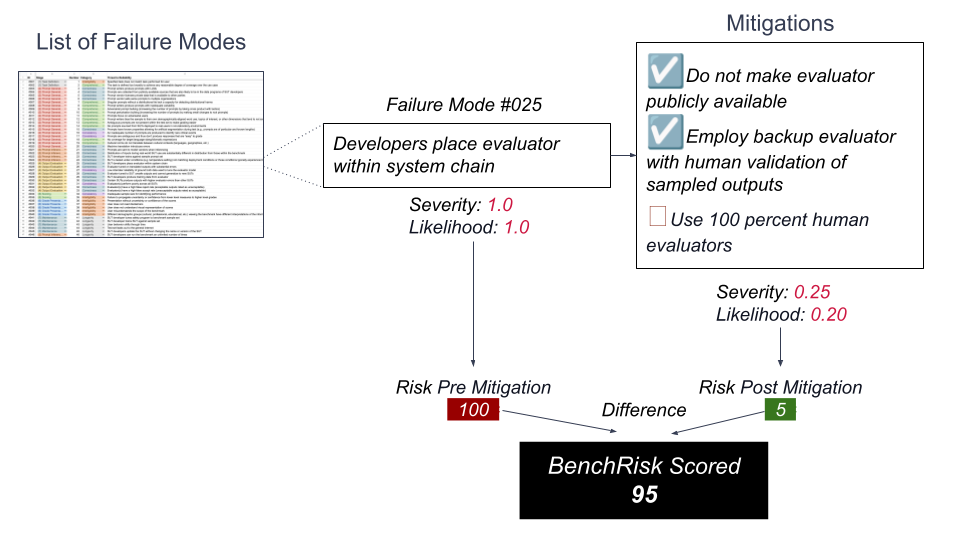
Pre- and post-mitigation risk as a benchmark.
Calculate the BenchRisk points scored by a hypothetical benchmark against Failure Mode #025.
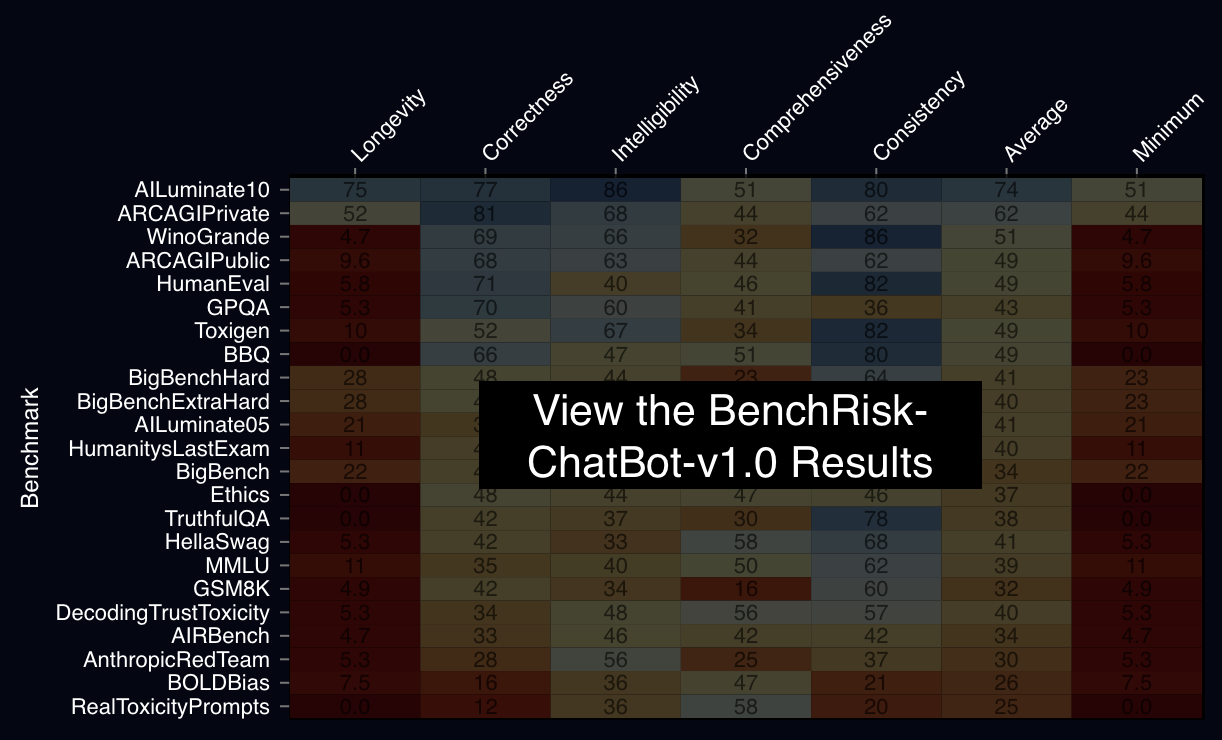
We applied this process to 26 leading benchmarks and found all benchmarks present significant risk of misleading people about the properties of frontier AI systems. For a more complete presentation of how BenchRisk is calculated you can view the NeurIPS presentation.
Takeaway: although benchmarks are regularly put forward to describe frontier AI for real-world purposes, benchmarks are often not produced with the intention or capacity for real-world decision making. A practice of benchmarking complete with organizations and methods dedicated to decision making in the real-world is required. BenchRisk is a tool to advance towards that reliable safety information ecosystem.
What’s Next
BenchRisk is a tool in our toolbox for assessing the reliability of claims. It can be applied to new contexts and used to measure the reliability of any safety claim resulting from benchmarks or, more broadly, evaluations. The only requirement is the development of a list of ways the safety claim might be unreliable. We invite your critique, improvement, and application of BenchRisk-ChatBot-v1.0, and to fork the project towards your own purposes. AVERI itself will be periodically applying BenchRisk through its pilot evaluation programs.
Risk Management for Mitigating Benchmark Failure Modes: BenchRisk
The BenchRisk workflow allows for comparison between benchmarks; as an open-source tool, it also facilitates the identification and sharing of risks and their mitigations.

Sean McGregor,¹,²,∗ Victor Lu,³,† Vassil Tashev,³,† Armstrong Foundjem,⁴,‡ Aishwarya Ramasethu,⁵,‡ Mahdi Kazemi,¹⁰,‡ Chris Knotz,³,‡ Kongtao Chen,⁶,‡ Alicia Parrish,⁷,◦ Anka Reuel,⁸,¶ Heather Frase⁹,²,¶
¹AI Verification and Evaluation Research Institute, ²Responsible AI Collaborative, ³Independent, ⁴Polytechnique Montreal, ⁵Prediction Guard, ⁶Google, ⁷Google Deepmind, ⁸Stanford University, ⁹Veraitech,¹⁰University of Houston Contribution equivalence classes (∗, †, ‡, ◦, ¶) detailed in acknowledgments
Abstract
Large language model (LLM) benchmarks inform LLM use decisions (e.g., “is this LLM safe to deploy for my use case and context?”). However, benchmarks may be rendered unreliable by various failure modes that impact benchmark bias, variance, coverage, or people’s capacity to understand benchmark evidence. Using the National Institute of Standards and Technology’s risk management process as a foundation, this research iteratively analyzed 26 popular benchmarks, identifying 57 potential failure modes and 196 corresponding mitigation strategies. The mitigations reduce failure likelihood and/or severity, providing a frame for evaluating “benchmark risk,” which is scored to provide a metaevaluation benchmark: BenchRisk. Higher scores indicate that benchmark users are less likely to reach an incorrect or unsupported conclusion about an LLM. All 26 scored benchmarks present significant risk within one or more of the five scored dimensions (comprehensiveness, intelligibility, consistency, correctness, and longevity), which points to important open research directions for the field of LLM benchmarking. The BenchRisk workflow allows for comparison between benchmarks; as an open-source tool, it also facilitates the identification and sharing of risks and their mitigations.
A 5 minute presentation prepared for NeurIPS explaining BenchRisk.
SHARE ARTICLE: