
Measuring Progress on AI Safety Practices
AVERI’s purpose (i.e., to make third-party auditing of frontier AI effective and universal) takes inspiration from, among others, the financial industry. However, financial auditors benefit from 700+ years of bookkeeping history. AI safety does not have comparable forms of safety expression against which audits might be conducted. In short, there is no “balance sheet for AI” where frontier AI companies could fill in numbers to arrive at a bottom line finding of safe or unsafe.
Neither AVERI nor the rest of the AI assurance ecosystem has a solution to the “balance sheet problem,” but we can — at least to some extent — measure our progress towards a reliable accounting of AI risk.

Without reliable measurement of AI systems, we cannot conclude a measured system is safe
Measuring the Reliability of Claims
In financial audits, the task is to verify claims of financial condition, but for AI systems, an auditor is tasked with verifying safety and security claims. Consider, for example, the claims below:
| Finance | AI Safety | |
|---|---|---|
| Claim | Liquid cash balance: $12,186,633 | Cybersecurity risk: negligible |
| Examined Evidence | Bank statement | Safety case, benchmarks, evaluations, internal process control documents, red team results, … |
A financial auditor can quickly verify cash on hand by checking bank statements, but safety claims quantitatively and qualitatively integrate many forms of evidence. Without the simplicity of receipts, AI safety claim verification is an exercise in weighing “how likely is this risk model to be wrong?”
In short, verification is an exercise in measuring the risk that safety claims are wrong and reliable evaluations serve to reduce that risk. Strong measures of evaluation reliability therefore enable better evaluations.
Risk Management for Benchmark Evidence: BenchRisk
To enable the measurement of evaluation reliability, we examined benchmarks as artifacts making claims and measured the risk that these claims might mislead people about the properties of a system. We bundled our process, which is a specialized form of risk management processes, into a dataset at BenchRisk.ai and presented the results at NeurIPS 2025.
McGregor, Sean, et al. Risk Management for Mitigating Benchmark Failure Modes: BenchRisk. Proceedings of the Neural Information Processing Systems Conference (NeurIPS), 2025. arXiv, arXiv:2510.21460.
BenchRisk proceeds by collecting failure modes (57 to date) and mitigations (196 to date) whose affirmation by the benchmark author increases the benchmark’s reliability and score of BenchRisk.
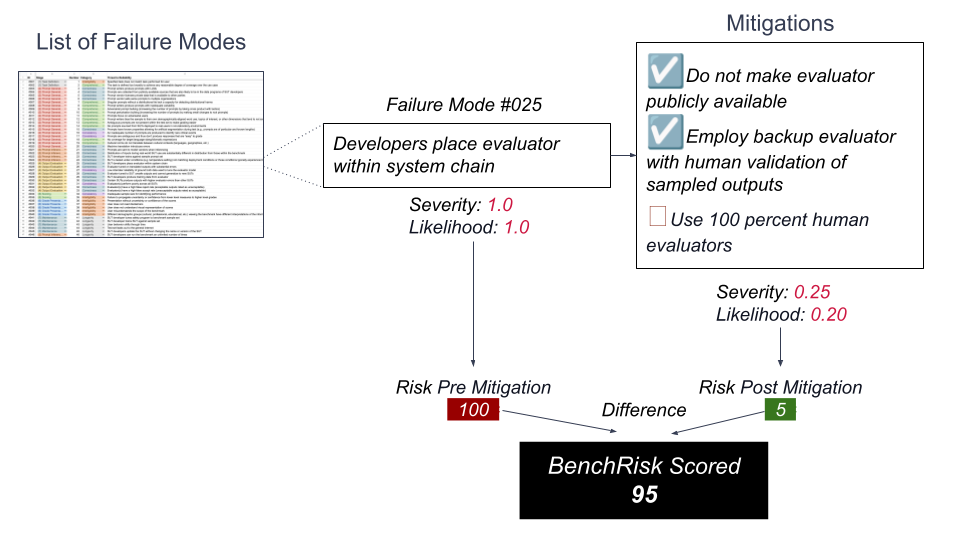
Pre- and post-mitigation risk as a benchmark.
Calculate the BenchRisk points scored by a hypothetical benchmark against Failure Mode #025.
We applied this process to 26 leading benchmarks and found all benchmarks present significant risk of misleading people about the properties of frontier AI systems. For a more complete presentation of how BenchRisk is calculated you can view the NeurIPS presentation.
Takeaway: although benchmarks are regularly put forward to describe frontier AI for real-world purposes, benchmarks are often not produced with the intention or capacity for real-world decision making. A practice of benchmarking complete with organizations and methods dedicated to decision making in the real-world is required. BenchRisk is a tool to advance towards that reliable safety information ecosystem.
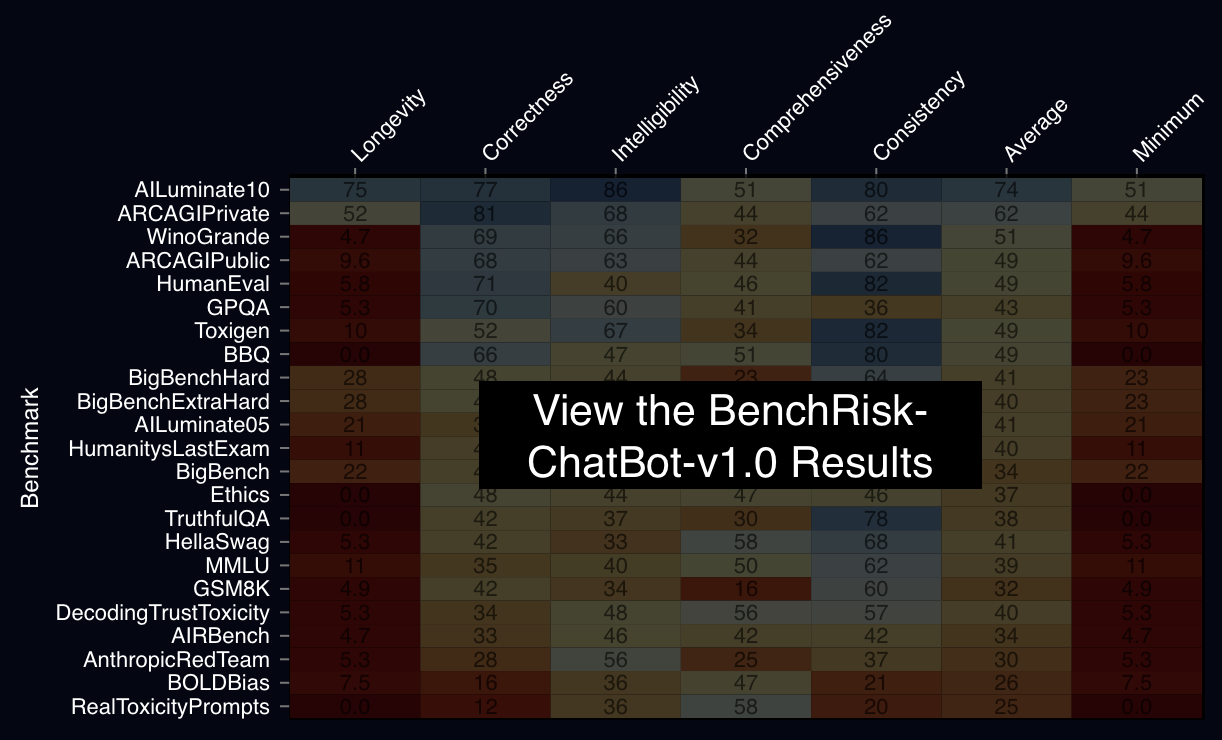
What’s Next
BenchRisk is a tool in our toolbox for assessing the reliability of claims. It can be applied to new contexts and used to measure the reliability of any safety claim resulting from benchmarks or, more broadly, evaluations. The only requirement is the development of a list of ways the safety claim might be unreliable. We invite your critique, improvement, and application of BenchRisk-ChatBot-v1.0, and to fork the project towards your own purposes. AVERI itself will be periodically applying BenchRisk through its pilot evaluation programs.