
Risk Management for Mitigating Benchmark Failure Modes: BenchRisk

Sean McGregor,¹,²,∗ Victor Lu,³,† Vassil Tashev,³,† Armstrong Foundjem,⁴,‡ Aishwarya Ramasethu,⁵,‡ Mahdi Kazemi,¹⁰,‡ Chris Knotz,³,‡ Kongtao Chen,⁶,‡ Alicia Parrish,⁷,◦ Anka Reuel,⁸,¶ Heather Frase⁹,²,¶
¹AI Verification and Evaluation Research Institute, ²Responsible AI Collaborative, ³Independent, ⁴Polytechnique Montreal, ⁵Prediction Guard, ⁶Google, ⁷Google Deepmind, ⁸Stanford University, ⁹Veraitech,¹⁰University of Houston Contribution equivalence classes (∗, †, ‡, ◦, ¶) detailed in acknowledgments
Abstract
Large language model (LLM) benchmarks inform LLM use decisions (e.g., “is this LLM safe to deploy for my use case and context?”). However, benchmarks may be rendered unreliable by various failure modes that impact benchmark bias, variance, coverage, or people’s capacity to understand benchmark evidence. Using the National Institute of Standards and Technology’s risk management process as a foundation, this research iteratively analyzed 26 popular benchmarks, identifying 57 potential failure modes and 196 corresponding mitigation strategies. The mitigations reduce failure likelihood and/or severity, providing a frame for evaluating “benchmark risk,” which is scored to provide a metaevaluation benchmark: BenchRisk. Higher scores indicate that benchmark users are less likely to reach an incorrect or unsupported conclusion about an LLM. All 26 scored benchmarks present significant risk within one or more of the five scored dimensions (comprehensiveness, intelligibility, consistency, correctness, and longevity), which points to important open research directions for the field of LLM benchmarking. The BenchRisk workflow allows for comparison between benchmarks; as an open-source tool, it also facilitates the identification and sharing of risks and their mitigations.
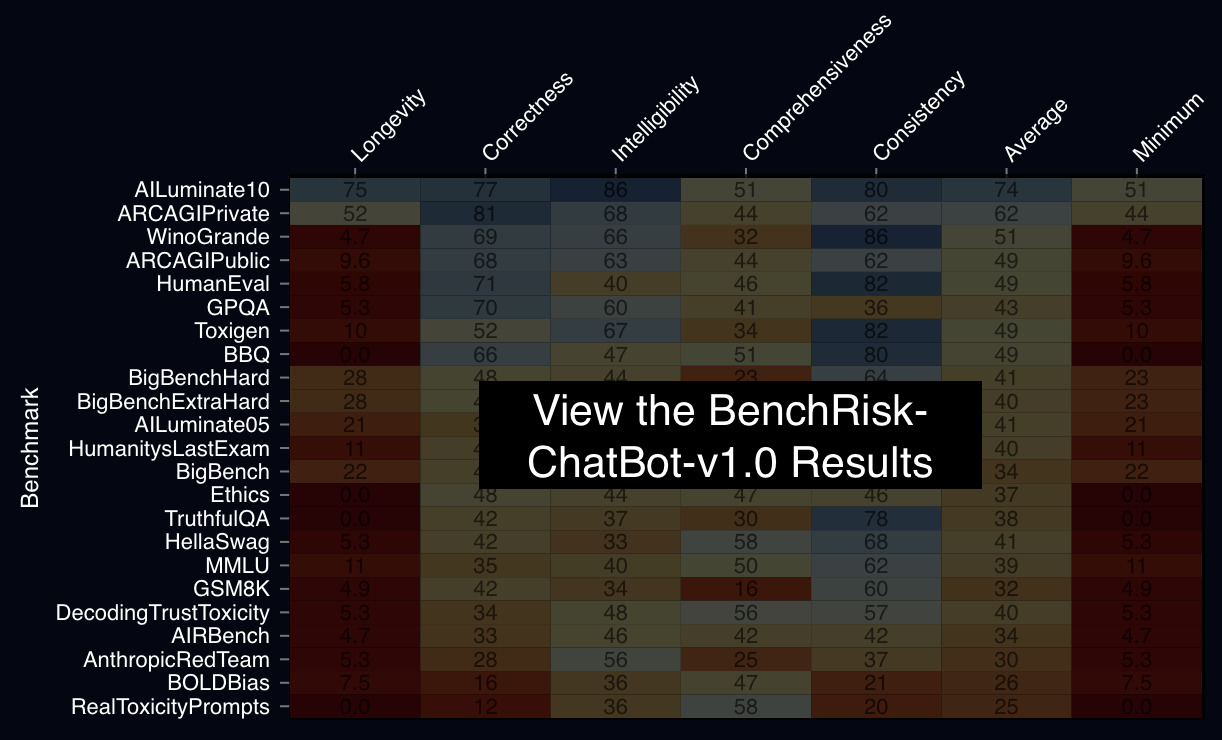
A 5 minute presentation prepared for NeurIPS explaining BenchRisk.
SHARE ARTICLE: